
Harnessing AI and MongoDB Atlas for Advanced Media Search for Enterprises
A one-shot search solution built inside Rocketium's asset management system

When you happen to work at scale, the problem set changes and you naturally start focusing on how we can help users navigate this large-scale data set that they have entrusted us with. And at Rocketium, we are all about that scale that we handle for Fortune 500 enterprises. Upon that same thought, we encountered a problem proposed to us by one of our clients. They asked -
“Can we search for the photoshoot image from last year where a female model was wearing an orange dress, we remember we uploaded it on Rocketium, but don’t remember the exact name of the image.”
Normally users were having a strong nomenclature to their images and for years they have been searching based on certain tags and names, sorting them by date and they were good to go. There was some manual effort involved, but no method existed for figuring out what was in that image. And that’s exactly what they wanted - If we can search their images by understanding the content of the image as well?
When I learnt about this problem surfacing, I was leading the development of our project workflow management tools which allow creative teams to streamline their project and asset management inside Rocketium, so that their designers have everything in one place. This search problem seemed interesting and I knew it could be done, I just had not thought how, but I had the zeal which runs in every engineer here - “We’ll figure out the tech to make this work” 💪
Our current architecture ⚙️
At Rocketium we use MongoDB as our primary database to store general user data like project data, asset metadata, etc and our assets reside in specific AWS S3 buckets for different users considering data privacy. Pretty standard stuff I’d say. I personally believe great engineers became great by leveraging the resources they had to the best use and not by reinventing the wheel every time they had a new problem. That’s what I had to do - enhance the existing infra with image content identification and search capabilities.
Now with this architecture, I had two ways to go about it → go make a presentation and present to the team that I can do it and convince them of whatever solution I proposed and then go build it OR I can just quickly build a prototype for them to have a look and feel of what I want to build in the product - I always chose the latter.
At Rocketium Engineering, we follow a culture which dictates that “Code wins over arguments”, so if you want the team to be convinced of your solution, the simpler way is to build out a proof of concept which will help you understand the problem better, and also the team to understand your solution better. The faster you can prototype, the faster you can get to the implementing part. That speed and agility are what I’ve learnt here, and I had just one week to research and prototype this.
Understanding the image content 🧠
The first part of solving the search problem was to identify what is in the image? One naive solution is to just implement any image recognition service like Google Vision and ask it to tag the images directly, but where’s the fun in that?
Any solution is worthless without adding the context of its application. We need to understand who is gonna use this feature and build it keeping that persona in mind, while keeping it flexible enough to cater to changing needs.
And for us, the context was that we deal with mostly advertisement campaign creatives which have a few elements - the model image, the product, a background, and the text (heading, subheading, offer text, and CTA text). All of these assets are separately stored in our media library which can be combined to build these ad creatives inside our campaign editor.
The power of image recognition in this context would come from actually being able to bifurcate the tags as well into categories. Remember what the customer asked us - “Can we search for the photoshoot image from last year where a female model was wearing an orange dress”. What if we could identify the products, colours, humans, and other things in the image and place them in separate categories so that users can search across these verticals! 🧐
We were already using Google Vision to get the tags for every uploaded image, but they weren’t that accurate, let alone categorisation. So I fed them to Chat GPT API and asked it to classify them into categories. It was smart enough, but not so much.

Next, I thought of training my own ML model for this and I figured out that Amazon Rekognition has Custom Labels which we can use to label our images with a custom dataset of labelled images.
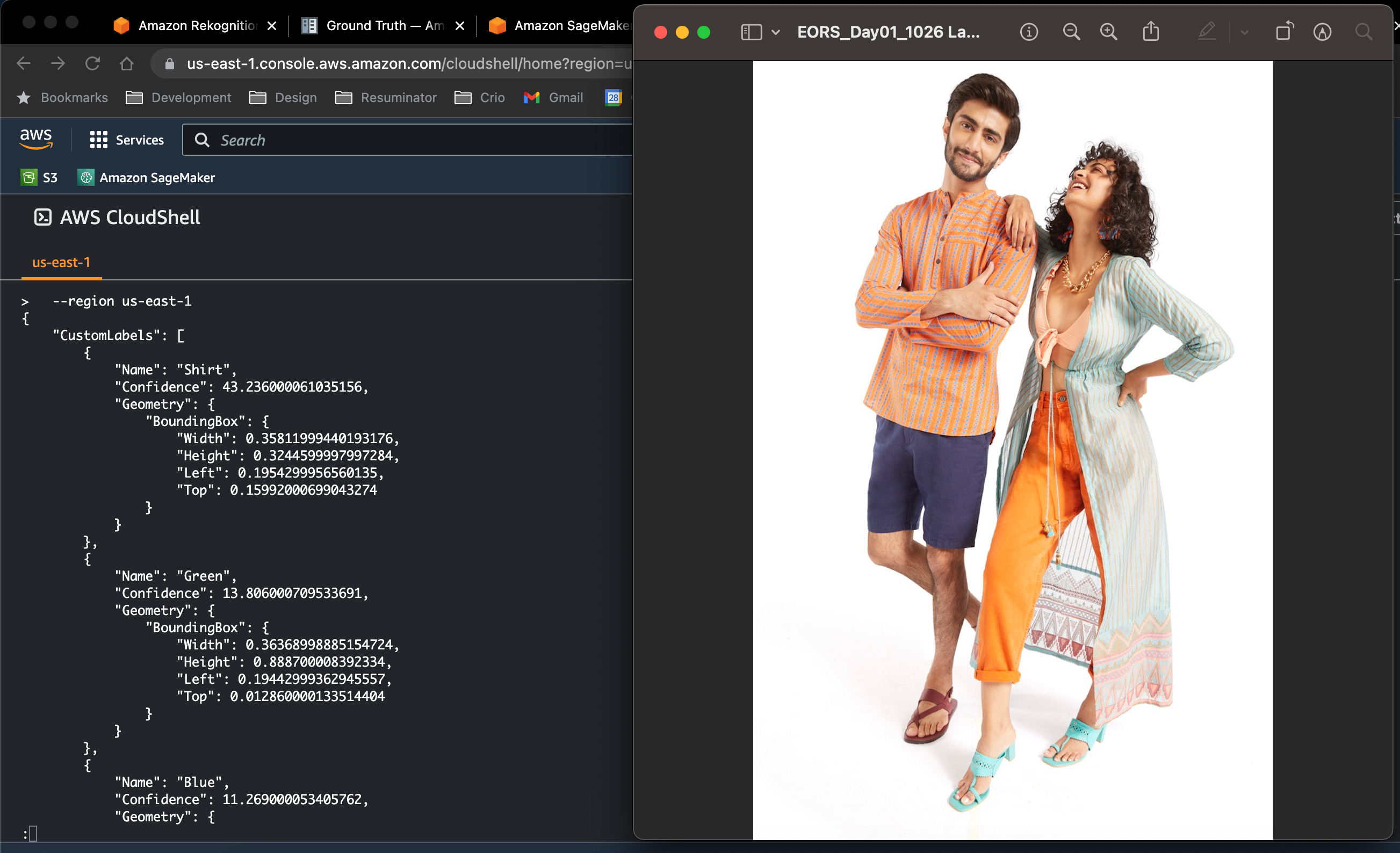
That worked decently well where the training set was just 20 images and the test set was 10 images. The model had an F1 score (or accuracy) of ~60% but there were two challenges with it:
We need a large variety of images to train the model of different types of products and human images.
We need to label the images manually to train on them, which will become a pain real soon because of the volume of images we handle.
Next, I thought, why not use the default pre-trained models from Amazon Recognition, this led to a realisation. Since Amazon and Rocketium kind of work in the same domain of e-commerce, where Amazon sells these items, Rocketium helps create ads which sell these items. We both need product and model image recognition for classification. 🤝
Amazon Rekognition works pretty well when it comes to identifying the products and humans, plus they have also classified their data into categories which an e-commerce site could benefit from. They also have the capability to identify dominant colours for the foreground and the background.
Tagging images with Amazon Rekognition 🏷️
Every image document stored in MongoDB has certain properties like name, URL etc, and I added a “customFields” key to it which would be an object that can store these key-value pairs
Amazon Rekognition gives an elaborate response when it comes to image labelling, now it was up to us on how we can utilise this data for our use case. Rekognition gives us a category of the label which I planned to map to the “customFields.product” key of the image metadata, and only selected the top 10 labels which were predicted with more than 75% confidence.

For the colours, I was taking “Foreground.DominantColours” returned from Rekognition and returning them as one of the 12 natural colours. The tags which were returned but did not fit the categories we mentioned earlier were returned as just “tags” for safekeeping.
The thing to note is that all of these tags were just suggestions for the Humans, generated by AI. No way that we were forcing these labels on the images. Once the labels are received, anyone doing the quality check (QC) could modify them, but they get a great starting point.
Searching through these tags 🔎
Now using the powers given to us by Amazon Rekognition and applying some JS magic, we were able to tag every image with a “product” list, and “colour” list, and assign some other properties to it as well through “tags”. But this was just half the story - the next one is even trickier. Enabling users to search images by just writing in a natural language like → “Orange dress woman” and get images of women wearing orange dresses!
There are two ways which every engineer on some research would find when it comes to searching for documents in MongoDB.
Sync your data with Elastic Search (with its mongo-connector) and use the full-blown powers of Elastic Search to search your data.
If you have a self-hosted MongoDB, then create a Text Index and then use the
$textoperator in the query to search through documents.
But there are two potential challenges with this as well, which I found during my research:
There is always a maintenance cost associated with introducing a technology and I wanted to keep it as minimal and light as possible so that it just works, without much maintenance effort.
The
$textSearch in Mongo is a full-word search, so if you plan to search “Chi” in a document which has the text, “The Chinese built the great wall of China”, it will not be returned in the result. But we needed a partial search as well if you also need autocomplete
Then? How do I achieve a powerful search functionality with autocomplete in my MongoDB collection?
Enter MongoDB Atlas Search ✨
Around 2020, MongoDB folks launched Atlas Search which comes with their cloud-hosted solution MongoDB Atlas. At Rocketium, we moved from a self-hosted solution to MongoDB Atlas, towards the end of 2022 with a humongous effort from Himanshu Garg and team. This enabled us to take advantage of Altas Search for this use case.
Apparently MongoDB Atlas and ElasticSearch both use the same technology under the hood which is - Apache Lucene and use similar concepts for building a search index. MongoDB Atlas seemed to be a great choice for us to build a search because -
There was minute maintenance overhead since we were already using and managing MongoDB Atlas for our db instances.
It did not require any separate infrastructure setup and we can just build queries for searching where our data already resided. No need for external syncing.
MongoDB Atlas automatically syncs the data and updates the search index for the newly added items. Set it and forget it.
The next challenge was to learn how to build and deploy a search index because apparently, that is not as simple as setting up Altas Search 😅
Building a search index for assets 📑
On the MongoDB Altas platform, you can create a search index which starts with a default value of:-
{
"mappings": {
"dynamic": true
}
}This will basically index everything in your documents and you can search on it, now while this may sound lucrative to do, it comes with the cost of heavy search indexes, and then speed.
Hence we disabled the dynamic mappings to give our own mappings, something like this
{
"mappings": {
"dynamic": false,
"fields": {
"customFields": {
"fields": {
"colors": {
"type": "string"
},
"products": {
"type": "string"
},
"tags": {
"type": "string"
}
},
"type": "document"
},
"name": {
"type": "string",
"analyzer": "lucene.standard",
"multi": {
"keywordAnalyzer": {
"type": "string",
"analyzer": "lucene.keyword"
}
}
}
}
}
}The above search index is explained as follows —
mappings: This section defines the schema for the search index.dynamic: The valuefalsemeans that the index won't automatically index new fields that get added to the documents in the future. Ifdynamicwastrue, then any new field added to a document would automatically be included in the search index.fields: This section describes the fields to be indexed.customFields: This is a document field (nested field) containing other fields.fields:colors,products,tags: These fields are set to be indexed as strings. This means that MongoDB will create a text index on these fields to allow text search.
name: This field is indexed as astring.string: This allows text search on thenamefield. This field is further analyzed by two analyzers.lucene.standard: This analyzer tokenizes text into terms (words), changes the tokens to lowercase and removes common English words.lucene.keyword: This analyzer treats the whole text field as a single term. This is useful for exact match searches.
Now depending on the use case, this search index could be different to support different applications.
Once this is saved, MongoDB will start creating a search index which can later be utilised in our code, and these fields could be searched with the $search operator.
This example query will match name and products from the defaultIndex and return the results which match. We use this query as one step in the MongoDB aggregation pipeline.
{
$search: {
index: "defaultIndex", // index name
compound: {
should: [
{
text: {
query: searchString as string,
path: "name",
fuzzy: {
maxEdits: 2,
},
},
},
{
text: {
query: searchString as string,
path: "customFields.products",
fuzzy: {
maxEdits: 2,
},
},
},
],
},
highlight: {
path: [
"name",
"customFields.products",
],
},
},
},Bonus 💡: This search index also allows us some typo tolerance by specifying fuzzy property with maxEdits, where we can specify how many characters can be misspelt in a word.
And the highlight field would return an object which can help you identify matched words in the search results.
And what about partial searching?
The way I designed this search index was to match exact words, but what about partial search as well? Well, that is covered under an Autocomplete index.
An autocomplete index helps in tokenising the text to search for partial parts of the text as well. It requires specifying “autocomplete” properties which help us fine-tune how we wish to build the index. Suppose we wish to just add autocomplete for the products field, the search index would look something like this —
{
"mappings": {
"dynamic": false,
"fields": {
"customFields": {
"type": "document",
"fields": {
"products": [
{
"type": "string"
},
{
"foldDiacritics": false,
"maxGrams": 8,
"minGrams": 2,
"tokenization": "edgeGram",
"type": "autocomplete"
}
]
}
}
}
}
}Where the rest of the things are the same, but the “type: autocomplete” object properties are explained as follows —
autocomplete: This type is specialized for providing autocomplete functionality. This means, as users start typing into the search field, suggestions that match their input will be displayed, enhancing the search user interface.
foldDiacritics: When set tofalse, this means the search will distinguish between characters with diacritics (likee,é,è, etc.) and their simple counterparts (likee).maxGramsandminGrams: These properties control the size of the text fragments (grams) that are indexed. In this case, the text will be broken into fragments that are at least 2 characters long (minGrams) and at most 8 characters (maxGrams) long. This affects how the autocomplete suggestions are generated.tokenization: It's set asedgeGram, which means the system will index the beginning fragments of the words. This is particularly useful for autocomplete functionality, where you want to match input from the start of a word.
This gives us two separate search indexes for exact match and partial match. We can keep both indexes combined in a single one as well, but that would just take more time to build since autocomplete indexes generally take longer to build.
Wrapping up
While MongoDB Atlas Search offers powerful full-text search capabilities, it comes with potential challenges related to cost, speed, and scalability, especially at a larger scale. As with any technology solution, it's essential to balance the requirements of functionality, cost-effectiveness, and performance.
But building an effective search within our media library was one of the most challenging and interesting problem statements I’ve worked on in the past year, and wrapping up the research and prototyping in a week was thrilling!
And btw this whole code is open-sourced if you wish to have a look - https://github.com/viveknigam3003/cross-search
Work at Rocketium
At Rocketium, you'll tackle complex challenges of scale, drive innovation, and shape the future of enterprise solutions. If you're passionate about problem-solving and eager to influence how enterprises manage data at scale, have a look at our careers page or drop a mail at careers@rocketium.com
More about the amazing culture we follow at Rocketium, have a look at culture.rocketium.com
A brilliant example on how we can use the latest tech at the perfect time and solve some real users problem.
It was fun knowing about this, and seeing it in action too.
Looking forward for more such posts from you.